(To) the FAIR Data Principles
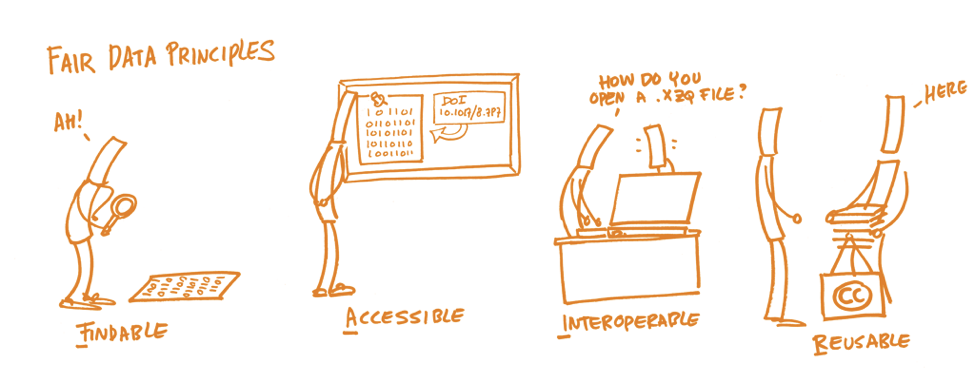
The FAIR Data Principles were created as guidelines to making data more reusable, both by humans and machines. They also promote more responsible data stewardship of valuable digital resources. FAIR stands for Findable, Accessible, Interoperable, and Reusable (Wilkinson et al., 2016).
Why should you care about FAIR?
It’s good for science and accumulating knowledge. Not convincing enough? It’s also good for you.
By making your research data findable to other researchers, you are also increasing the findability of your work, and potentially increasing your impact.
By ensuring that others can easily access and work on your data, you are also ensuring that your future self will be easily(ish) able to access and work on your data.
By increasing interoperability, you are ensuring that others, especially those from related fields, can readily integrate your work into their workflow and encourage collaboration.
By making it easier for other researchers to reuse your data, you are also increasing the likelihood that they will actually reuse your data, and not give up because they have to jump through hoops to do this. Just remember to provide a clear license and citation so that you get credit for your work!

Definition of the FAIR Principles
Findable means you can actually locate the (meta)data. This requires the data to be:
- assigned a persistent identifier (PID)
- accompanied by metadata
- registered in a searchable resource.
Accessible means there should be a clear path to accessing the (meta)data. Preferably accessible via:
- an open, standardised protocol.
- restricted access (authentication), if necessary.
Interoperable means the (meta)data should be in a format that allows them to be used in common applications and workflows, preferably with:
- formal, accessible, broadly applicable language
- vocabularies that follow FAIR principles
- references to other related (meta)data
Reusable means the data should be well-documented, including:
- domain-relevant guidance using community standards for researchers who wish to reuse the data
- provenance of their creation
- a license to indicate the terms of reuse
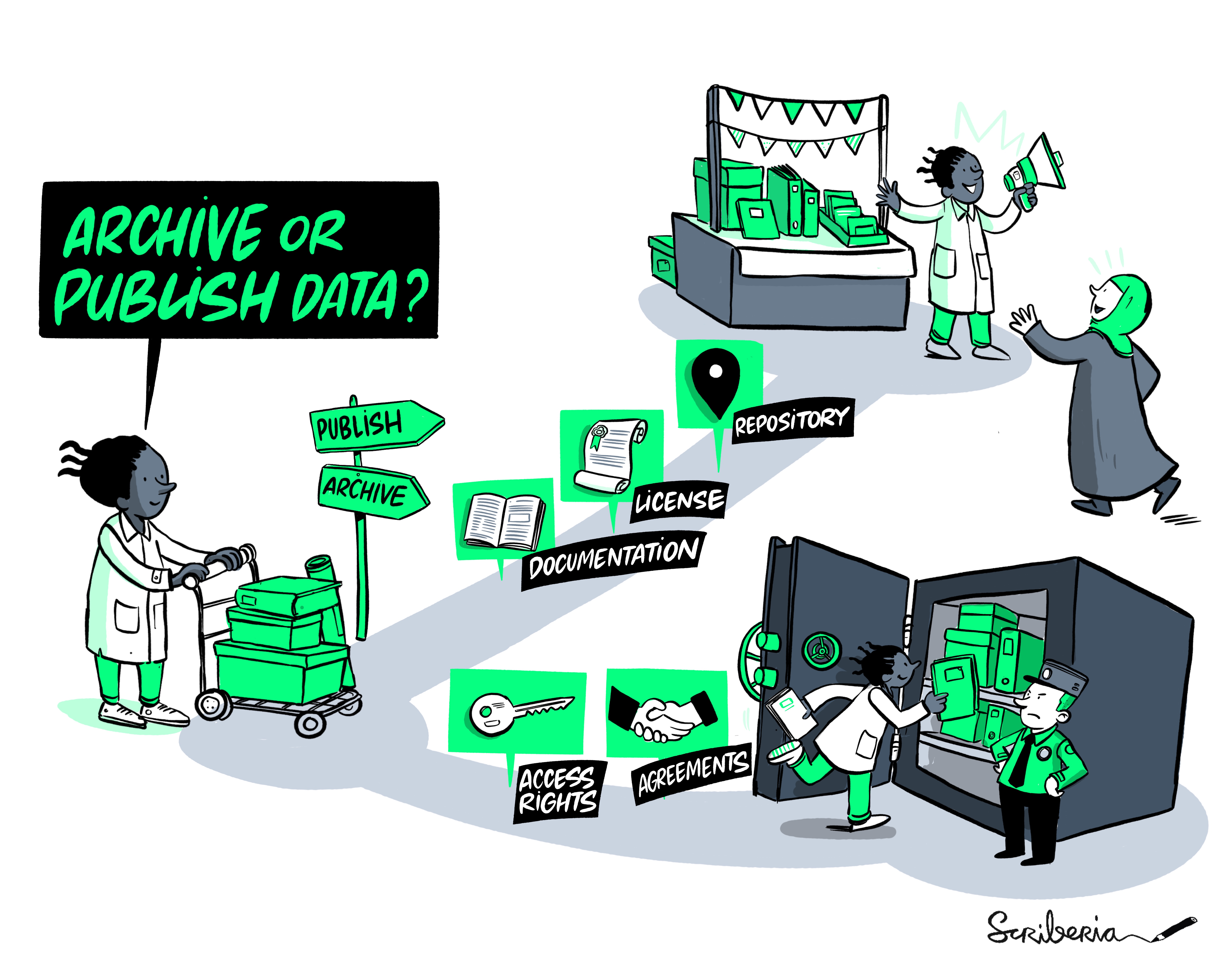
Putting principles into practice
Things to ask yourself:
- Can someone search for and find your data?
- Do the data have a unique persistent identifier that you can refer to when communicating your findings?
- Once someone finds your data, can they be downloaded or accessed in any way?
- can information about your data be found, even if the dataset no longer exists?
- Once the data have been obtained, can they easily be integrated into existing workflows?
- Is it clear how researchers should re-use the data, and how they are allowed to do this?
- How should they give you credit when re-using the data?
I have found that it helps to prepare FAIR data by working backwards through the FAIR principles.
It all starts by ensuring your data are reusable. Proper documentation early on is much easier to do when the data are fresh in your memory. The most basic form of documentation is a README. This can be a plain-text (README.txt) or markdown (README.md) file. Here, you should describe the project and the data, including the methodology of data collection and a description of the variables (data dictionary). It may also be useful to add how the data can be accessed and what software might be needed to work with the data. For more information, see https://www.makeareadme.com/.
Documenting the analytical workflow is also important for reuse. This can be done using using code notebooks such as Jupyter, R Markdown, or Quarto (my personal favourite).
Making sure your data can be easily integrated into workflows (interoperable) requires using tools and data vocabularies that are standard to your field. To ensure wider adoption of the data, you should also be using free and open source tools and formats (for example, export your data as a CSV file rather than an Excel spreadsheet).
Making the data accessible is as easy (or difficult) as uploading them to a trusted data repository. The best way to choose is by exploring what repositories others in your field use. There are also general purpose repositories like Zenodo. You can find useful information on (trusted) repositories on re3data.
Finally, to make your data findable, you should make sure to include the persistent identifier in your research article (Data Availability Statement). Often the data repository will allow you to reserve a DOI for your dataset. This means you can wait to publish your data until the manuscript has been accepted. Simply add the reserved DOI to your article, and then make the repository public when the manuscript has been accepted/published. Avoid using an email address for contact, or a personal/group website as the (only) data repository. These are more susceptible to change than, for example, an ORCID and a Digital Object Identifier (DOI) (though, these are also not foolproof).
What a repository can do for you
Repositories have the infrastructure to ensure long-term storage of your dataset. Zenodo, for example, is funded by CERN and OpenAIRE, among others. CERN has also committed to hosting the repository for the lifetime of CERN itself. Repositories also provide you with a persistent identifier and register your repository metadata in searchable resources. They implement access protocols for both humans (a nice big ‘Download’ button) and computers (Application Programming Interface).
Repositories will make it easy to adhere to general metadata standards (during the upload process you provide information about your data), and some repositories will enforce field-specific metadata standards. They will also track the (re-)usage (views, dowloads, citations) and display the license and recommended citation.
Common misconceptions
FAIR = Open
There are many reasons why a dataset cannot (and should not) be openly available. Many repositories allow you to restrict access to your dataset. In these cases, there should be a clear process of requesting access to the data, that can be updated on the repository. A statement of
The data are available upon request.
at the bottom of your article is not a clear process and cannot be updated with new contact information when needed. The data are also not very findable.
I use the supplementary materials of journals. Isn’t that FAIR enough?
The persistent identifier is often the same as the article, which means that the data do not have a unique identifier required to be findable. Access to a journal article’s supplementary materials may also be stuck behind a paywall. They also rarely have access procedures for computers (e.g. API). Supplementary materials are often in the form of a PDF document. This is not very interoperable and very difficult to reuse.
I still have questions!?
Where can you go for more help? Most institutions have dedicated (and passionate!) people working on promoting research data managment (including FAIR) and Open Science. These can be Data Stewards or (Digital) Librarians. Try to find them at your institute and reach out! Otherwise The Turing Way is also a good place to start.